When you average information from your neighbors, and your neighbors are mostly wrong, you get worse — not better.
That sentence sounds obvious when you read it. But an entire class of machine learning models does exactly this, billions of times per second, on some of the most important data structures in computer science. This post is about what happens when we tried to fix that, where it worked, and — honestly — where it didn’t.
What Are Graph Neural Networks?
A graph is a collection of things (nodes) connected by relationships (edges). Social networks, molecules, citation databases, web pages — all graphs. A graph neural network (GNN) is a neural network that learns by aggregating information from neighbors in a graph. Each node looks at what its neighbors look like, combines that with its own features, and updates itself. Stack a few layers of this, and information flows across the graph.
The key operation is aggregation: take your neighbors’ features, average them, and use the result to update yourself. This is sometimes called “message passing” — nodes send messages to their neighbors, and each node reads its inbox to decide what it is.
The Problem: When Neighbors Disagree
This works beautifully when connected nodes tend to be similar — papers cite related papers, friends share interests. This property is called homophily (“love of the same”), and most popular GNN architectures were designed with it in mind.
But not all graphs are homophilous. In fraud detection, fraudsters connect to legitimate users, not to each other. In dating networks, well, you get the idea. When connected nodes tend to have different labels, the graph exhibits heterophily (“love of the different”).
Here is the concrete failure mode. Suppose you are a node in class A, and 80% of your neighbors are class B. A standard GNN averages your neighbors’ features and hands you the result. That average looks like class B. You just got worse at knowing you are class A. The graph structure that was supposed to help you has actively misled you.
This is not a theoretical concern. On heterophilous benchmark datasets, a plain MLP (a multi-layer perceptron — a neural network that completely ignores the graph and only looks at each node’s own features) often beats GNNs. The graph is hurting, not helping.
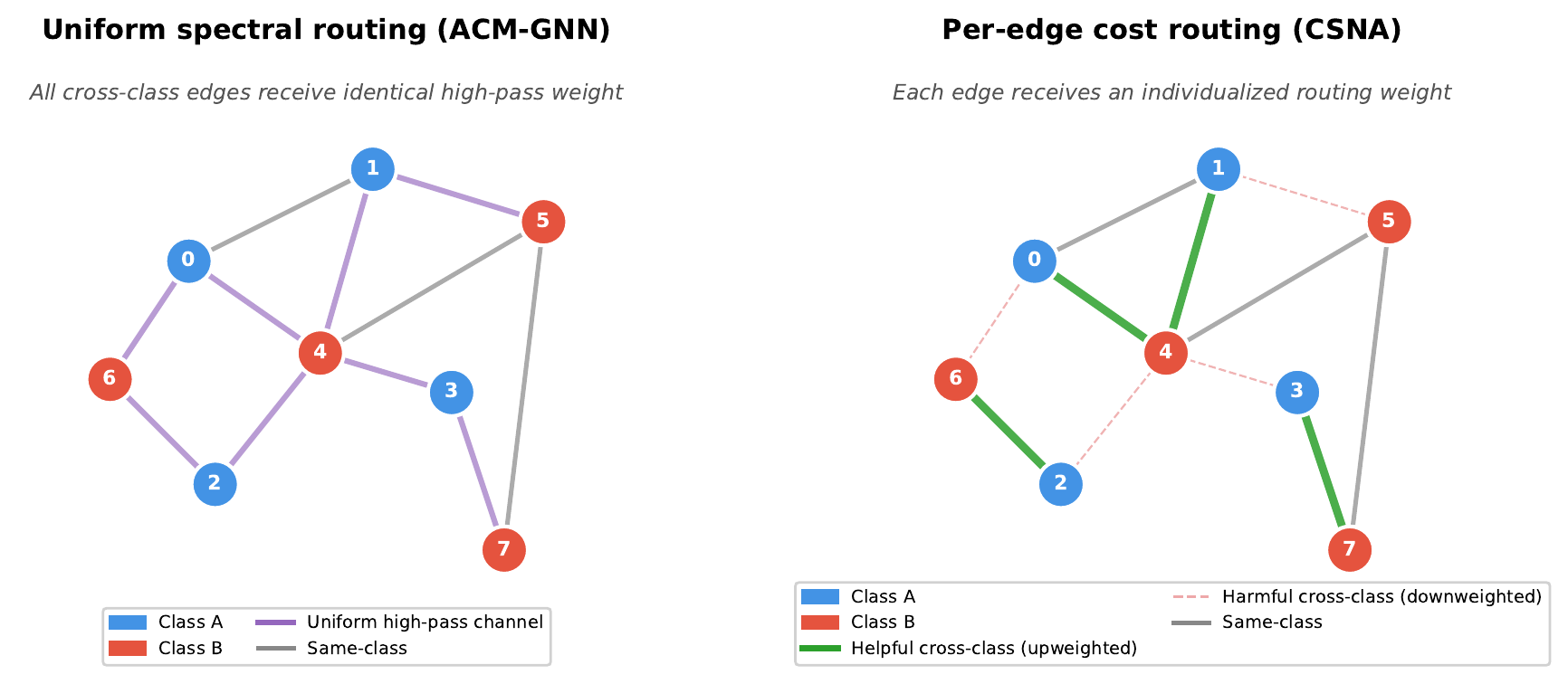
Our Idea: Route Neighbors by How Different They Look
The core insight behind our method, CSNA (Cost-Sensitive Neighborhood Aggregation), is simple: before you aggregate, measure how different each neighbor looks from you in a learned feature space. Then route neighbors through different channels depending on that measurement.
For each edge, we compute a cost estimating how likely two connected nodes are to disagree. This cost has two parts: one based on how different the nodes’ current representations look (observable divergence), and one the model learns (a heuristic estimate of unreliability). The default version uses only the observable divergence; an optional extension adds the learned estimate, but in practice we found the simpler version works just as well.
Based on this cost, each neighbor’s message gets soft-routed into one of two channels:
- A concordant channel for neighbors that look similar to you (low cost) — these get standard aggregation, because they probably agree with your label.
- A discordant channel for neighbors that look different (high cost) — these get a separate transformation, because blindly averaging them in would dilute your signal.
A learned gate then decides, for each node, how much to trust each channel versus its own features. On a heterophilous graph, the model can learn to down-weight the concordant channel (few useful same-class neighbors) and up-weight its own features or the separately-processed discordant signal.
Where It Worked — and Where It Didn’t
We tested CSNA on six standard heterophily benchmarks, comparing against seven baselines including GCN, GAT, GraphSAGE, MLP, and several methods specifically designed for heterophily (H2GCN, GPRGNN, ACM-GNN).
The wins. On the adversarial-heterophily datasets, CSNA was competitive with the best methods. It achieved the highest accuracy on Cornell (72.7%) and was statistically tied for first on Actor (35.7% vs. GPRGNN’s 36.0% — within one standard deviation). On Texas (77.0%) and Wisconsin (79.6%), it was within a few points of the best. All methods were tuned over the same hyperparameter grid for a fair comparison.
The failures. On Chameleon and Squirrel, CSNA scored 54.6% and 37.8% respectively — well below plain GCN, which hit 67.3% and 53.4%. This was not just our method failing; every heterophily-specific method (H2GCN, GPRGNN, ACM-GNN) also lost to GCN on these two datasets.
The Failure Is the Finding
Why does CSNA fail on Chameleon and Squirrel? Because there are two fundamentally different kinds of heterophily, and our method only handles one.
Adversarial heterophily is when your different-class neighbors are genuinely misleading. Their features look nothing like yours, and averaging them in corrupts your signal. On datasets like Cornell and Texas (small university webpage networks), this is the dominant pattern. CSNA handles this well — it identifies misleading neighbors by cost and routes them away from the main aggregation.
Informative heterophily is when being connected to different-class neighbors is itself a useful signal. On Chameleon and Squirrel (Wikipedia article networks), the pattern of which classes your neighbors belong to is highly informative, even though those neighbors have different labels. A node surrounded by class B and class C neighbors might reliably be class A — not because B and C features help, but because the structure of having B and C neighbors is the clue. Standard GCN captures this structural information through its aggregation. CSNA, by trying to separate and re-route different-looking neighbors, actually disrupts the structural signal that makes these datasets learnable.
This distinction — adversarial vs. informative heterophily — is not new to our paper, but our results make it concrete. If a cost-sensitive routing method helps on your dataset, your heterophily is probably adversarial. If it hurts, the heterophily is probably informative, and you should use a method that preserves structural patterns rather than filtering them.
What We Learned
Three takeaways from this work:
Not all heterophily is the same. The label “heterophilous graph” hides a crucial distinction. Methods that assume different-class neighbors are harmful will fail when those neighbors are informative. The field needs better ways to characterize what kind of heterophily a graph exhibits before choosing a method.
Honest failure analysis is underrated. Reporting where and why CSNA fails told us more about the problem than the wins did. The two failing datasets are exactly where the entire “route-by-similarity” paradigm breaks down.
Simple mechanisms can be diagnostic tools. The cost function’s ability (or inability) to separate edge types serves as a diagnostic for the heterophily regime — revealing what kind of graph you’re dealing with before committing to an architecture.
“Cost-Sensitive Neighborhood Aggregation for Heterophilous Graphs: When Does Per-Edge Routing Help?” by Eyal Weiss, Technion. arXiv preprint, 2026.
Code and data: github.com/eyal-weiss/CSNA-public